Understanding AWS Lambda Event Source Mapping
Attending AWS re:Invent is always a highlight for me, and this year’s session,
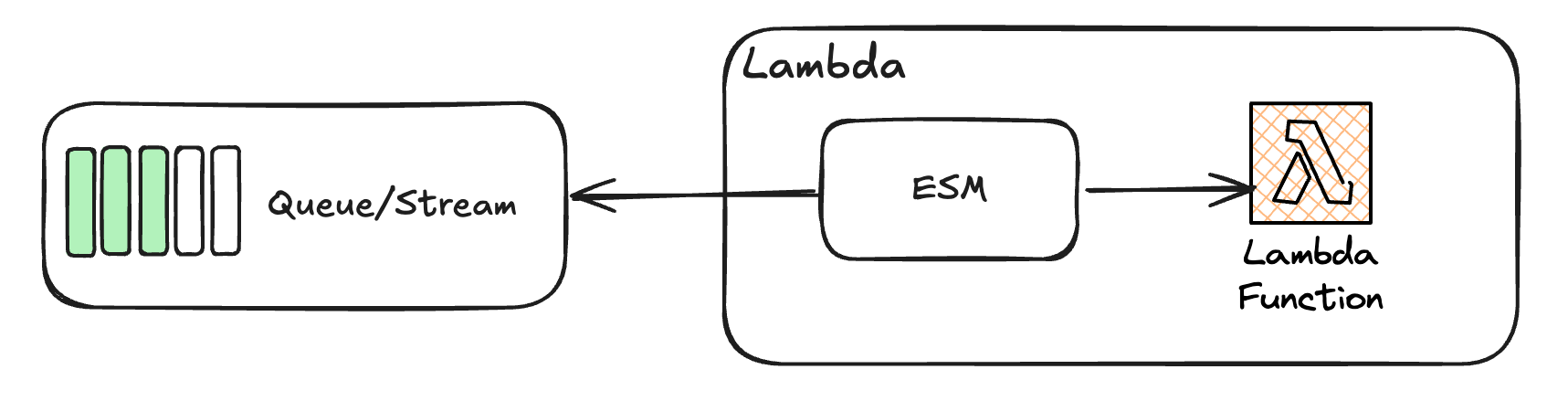
Table of Contents
- The Fundamentals: Event Source Mapping in AWS Lambda
- Partition Key Management: The Core of Event Order
- Error Handling in Distributed Systems: Preventing Bottlenecks
- Performance Optimization: Parallelization, Batch Processing, and Scaling
- Kinesis-Specific Features: A Competitive Edge
- Scaling Challenges: Balancing Upstream and Downstream Loads
- Best Practices: Building Robust Event-Driven Systems
- Final Thoughts
The Fundamentals: Event Source Mapping in AWS Lambda
To kick things off, the speaker provided an overview of how AWS Lambda integrates with event sources through ESM. Event source mapping ensures that Lambda functions are automatically triggered as new events arrive, making it a crucial component for real-time and asynchronous workloads. The session quickly moved into advanced topics, focusing on optimizing performance, ensuring fault tolerance, and managing error scenarios.
Partition Key Management: The Core of Event Order
One of the key concepts covered was partition key management in systems like Amazon Kinesis and DynamoDB Streams. These partition keys play a vital role in ensuring order and scalability:
Sequential Processing Within Shards:
Events with the same partition key are processed sequentially within their shard. This guarantees that related events (e.g., all transactions for a user) are handled in order. However, if retries or failures cause events to arrive out of order, consistency issues can arise.
Shard Behavior:
Shards are responsible for processing sets of partition keys, and they scale horizontally to handle increased event volumes. Even as the system scales, the partition key ensures that related events are processed within the same shard, preserving order.
This deep dive reinforced the importance of designing systems with careful consideration of partition key selection to balance performance and maintain order.
Error Handling in Distributed Systems: Preventing Bottlenecks
Error handling emerged as a critical focus area in the session. Distributed systems, especially those processing real-time event streams, require robust strategies to handle failures without cascading effects. Key insights included:
Infinite Retries and Dead Letter Queues (DLQs):
Without proper error handling, a shard encountering persistent errors could end up in an infinite retry loop, stalling other events in the shard. Routing unresolvable errors to DLQs, such as SQS or S3, ensures failed events are isolated and can be analyzed or resolved manually.
Failure Isolation:
Kinesis-specific event source mappings allow retrying failed records individually or in smaller batches. This prevents an entire shard from stalling due to one problematic record.
These practices are invaluable for maintaining the reliability of event-driven systems while ensuring that errors are handled gracefully.
Performance Optimization: Parallelization, Batch Processing, and Scaling
The session also addressed parallelization and batch processing, two critical levers for optimizing performance in Lambda-based architectures:
Parallelization Factor:
The parallelization factor controls how many workers process events from a single shard concurrently. While a higher factor improves throughput, it can introduce challenges in maintaining event order across partition keys. The speaker emphasized tuning this setting to match workload complexity and downstream capacity.
Batch Processing and Error Mitigation:
Features like bisect batch on error allow Lambda to split failed batches into smaller subsets, isolating problematic records for retries. This reduces redundant retries and improves system efficiency.Additionally, batch item failure reporting lets Lambda identify specific records in a failed batch, ensuring only those records are retried or sent to a DLQ.
Kinesis-Specific Features: A Competitive Edge
The session highlighted several features unique to Amazon Kinesis that make it particularly powerful for event-driven architectures:
Error Recovery:
With tools like checkpointing and offset management, Kinesis ensures graceful recovery from errors without reprocessing already-successful events.
Batch Item Failure:
This feature complements bisect batch by isolating failed records within a batch, making retries even more precise.
The speaker contrasted these capabilities with Kafka, noting that while Kafka offers flexibility, it lacks the granular error-handling features natively provided by Kinesis. Developers using Kafka often have to build custom solutions for similar functionality, increasing complexity.
Scaling Challenges: Balancing Upstream and Downstream Loads
Scaling event-driven architectures can be tricky, especially when traffic spikes or downstream systems face capacity limits. Key points included:
Handling Traffic Spikes:
Lambda and Kinesis scale efficiently to handle spikes, but parameters like shard count, parallelization factor, and batch size need fine-tuning.
Downstream System Limits:
Scaling upstream services is relatively easy, but downstream systems like databases or APIs often have rate limits. Strategies like throttling, backpressure mechanisms, and pre-filtering events can prevent overwhelming these systems.
Record Filters:
Pre-filtering events at the Kinesis or Lambda level ensures only relevant events are processed, reducing unnecessary load on downstream components.
Best Practices: Building Robust Event-Driven Systems
To wrap up the session, the speaker shared actionable best practices for building and maintaining event-driven architectures:
-
Set Up DLQs and Monitoring: Always configure DLQs for unresolved errors and monitor them for analysis. Use alarms to track error rates and address issues proactively.
-
Tune Parallelization Factor: Match the parallelization factor to your workload complexity and downstream capacity to optimize throughput.
-
Monitor Metrics: Regularly monitor metrics for Lambda, Kinesis, and downstream systems to identify bottlenecks and failure patterns.
-
Batch Size Optimization: Adjust batch sizes to balance latency, throughput, and error isolation based on workload characteristics.
-
Graceful Error Handling: Leverage features like bisect batch on error, batch item failure, and retry strategies to handle errors without disrupting the entire pipeline.
Final Thoughts
The SVS407-R session at AWS re:Invent was a deep dive into the intricacies of AWS Lambda event source mapping. From partition key management and error handling to performance optimization and scaling strategies, the session provided a wealth of practical knowledge for building robust, scalable event-driven systems.
One of the biggest takeaways for me was the importance of balancing throughput, order guarantees, and error isolation. Whether you’re processing billions of events with Kinesis or handling asynchronous workflows with SQS, these strategies can make all the difference in ensuring system reliability and efficiency.
AWS re:Invent continues to deliver world-class learning experiences, and this session was no exception. I’m excited to apply these insights to my projects and see the impact firsthand. If you’re building event-driven applications, I highly recommend exploring these features and best practices.